Using large language model to aid in teaching medical imaging report writing.
Chen Y, Xiang P, Zhou Q, Li C, Zhang X, Wang J, Wang H, Gao Z, Yang Z, Ye S, Taylor D, Feng ST.
Medical Teacher. 2025 Dec 26. DOI: 10.1080/0142159X.2025.2603353
https://www.tandfonline.com/doi/full/10.1080/0142159X.2025.2603353?af=R#abstract
はじめに
医学画像教育において、画像を正確に読影し標準的なレポートを作成する能力は必須のスキルである。しかし、効果的な教育方法の確立は依然として課題となっている。特に初学者は診断レポート作成に困難を抱えており、臨床現場では指導医が適時フィードバックを提供することで質の向上を図っているが、教室では1人の教員が20名以上の学生を担当する状況も珍しくなく、個別のレポートを詳細に査読してタイムリーなフィードバックを提供することは現実的に困難である。この教員の対応能力と学生のフィードバック期待との間のミスマッチが、医学画像教育における不協和音となっている。
研究の目的と方法
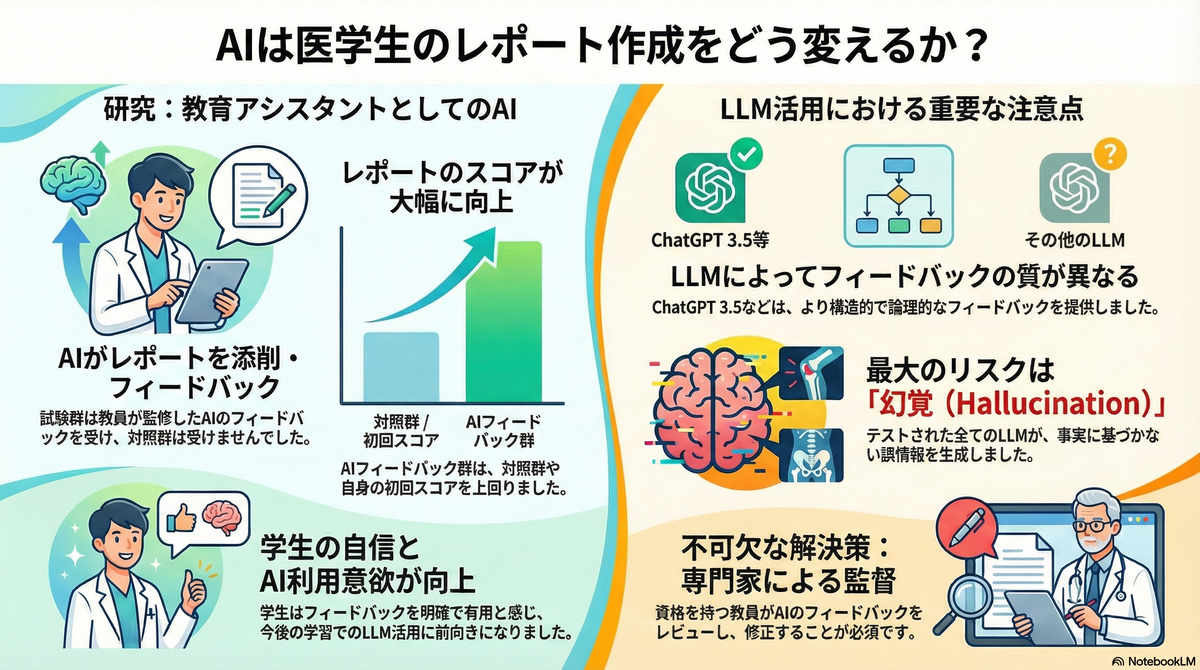
本研究は、中国・中山大学第一附属医院放射線科のチームが実施したもので、複数の無料LLMを比較評価し、どのモデルが最も効果的なフィードバックを提供するか、そしてLLM生成フィードバックが学生の画像診断レポートの正確性と標準化を改善できるかを検証した。
2024年4月に実施された本研究では、3年次学部学生をテスト群(30名)とコントロール群(30名)にランダムに割り付けた。テスト群の学生は典型的な教育症例に基づいて画像診断レポートを作成し、LLM生成フィードバックを受けた後、再度レポートを作成した。一方、コントロール群はLLMフィードバックを受けずに同じ症例のレポートを作成した。
使用したLLMと評価方法
研究では以下の4つの主要な無料LLMを評価対象とした:
- ChatGPT 3.5
- Claude 3 OPUS
- ERNIE Bot v3.5
- Tongyi Qianwen v2.5
LLMへのプロンプトは、学生の診断と記述、標準解答、そしてレジデント研修試験の採点基準の要点を組み合わせて設計された。フィードバックの質は、構造、内容、結論、ハルシネーション(幻覚)の4つの観点から評価された。
学生のレポート評価には、レジデント研修試験の採点システムを使用し、病変の記述、その他の所見の記述、記述の専門性、診断の正確性と優先順位付け、さらなる検査や治療の推奨などの項目を100点満点で評価した。
主要な研究結果
LLM間の比較
ChatGPT 3.5、ERNIE Bot v3.5、Tongyi v2.5は、Claude 3 OPUSと比較して、より良好な構造と論理性を示した(Mann-Whitney U検定、p < 0.05)。ただし、すべてのLLMにある程度のハルシネーションが認められた。
具体的には、ChatGPT、ERNIE Bot、Tongyiは以下の点で優れたパフォーマンスを示した:
- 明確で論理的に一貫したフィードバックの提供
- 学生の解答と標準解答の相違点の認識
- 適切な改善提案の提示
一方、Claudeのフィードバックは高度に一般化されており、効率的にターゲットを絞ったフィードバックを提供する点で劣っていた。
学生レポートの質的改善
テスト群の学生は、フィードバック受領後、以下の点で有意な改善を示した:
- 主要な画像所見の記述の向上
- 記述の専門性の向上
- さらなる臨床検査や治療に関する提案の増加
- 総合スコアの上昇(フィードバック前と比較してp < 0.05)
さらに、テスト群のレポートスコアは、コントロール群と比較してすべての評価項目で有意に高かった(t検定、p < 0.05)。
学生の意識調査結果
アンケート調査では、以下の傾向が明らかになった:
- 大多数の学生がLLMの存在を知っていたが、医学学習に使用した経験はなかった
- フィードバックは明確で組織化されており、十分な指導を提供すると評価
- 一部の学生は提案が冗長であると感じた
- この試みの後、多くの学生が今後の学習でLLMを積極的に使用する意欲を示した
考察:LLM活用の課題と注意点
ハルシネーション問題
ハルシネーションはすべてのLLMに共通する問題である。本研究では以下の2つの主要な形態が観察された:
- 虚偽情報の生成:LLMが存在しない記述を学生の解答に捏造し、その不正確な情報に基づいてフィードバックを生成する
- 論理エラー:学生の誤った解答を正解の代替的記述として認識してしまう
興味深いことに、異なるLLMは一貫したハルシネーションパターンを示す傾向があり、これはトレーニングデータセットの違いに起因すると考えられる。例えば、あるLLMは「クモ膜下腔の拡大は脳脊髄液循環の閉塞による」という誤った記述を繰り返し生成したが、実際には血腫が脳実質を圧迫することによる所見である。
論理的整合性の限界
LLMは論理的ルールを真に理解しているわけではなく、文脈内学習が正解に到達する可能性を高めているに過ぎない、いわば「推測」を行っていると考えられる。このため、以下の困難が観察された:
- 標準解答と比較して要点が欠けている場合は特定しやすいが、学生の解答に余分な誤記述が含まれている場合は検出困難
- 所見の病態生理学的意義の認識が困難
- 不正確な解釈や判断を生成することがある
再現性の問題
研究では、LLMが一貫した再現性を達成することに困難を抱えていることも判明した:
- 異なるバージョンのLLMは同じプロンプトで異なるフィードバックを提供
- 同じバージョン(例:ChatGPT v3.5)でも、マイナーアップデート後に口調や構造が異なるフィードバックを生成する可能性
効果的なプロンプト設計の重要性
明確で包括的なプロンプト設計が効果的なフィードバックを得るために不可欠である。本研究では、標準解答と画像診断レポートのすべての要点を組み合わせた構造化されたプロンプトを設計した。このような固定化された実行可能なプロンプトを学生に提供することで、自習時にも効果的なフィードバックを得られる可能性がある。
医学教育への示唆
教員監督の必要性
LLMは学生が自己のレポートを批判的に評価し、報告スキルを向上させるのを支援できるが、ハルシネーションや不正確さが依然として観察されるため、専門教員による監督が不可欠である。教員は以下の役割を担う必要がある:
- LLM生成フィードバックの正確性の検証
- ハルシネーションや論理エラーの特定と修正
- 学生が誤解を受けないようにする質の管理
カリキュラムへの統合
本研究では1~2回のフィードバック教育にとどまったが、この方法をコース設計に統合することで、より良好な成果が期待される。短期的改善(試験スコアの向上など)と長期的スキル開発を明確に区別する必要がある。
ハルシネーション軽減戦略
- 安定したローカルLLMの展開
- カリキュラム教材に基づく検索拡張生成(RAG)の使用
- より高度なモデル(例:ChatGPT-4o)の使用
- 相対的に固定されたバージョンのLLMと確立されたプロンプトの使用
限界と今後の課題
- フィードバックの評価側面が文献と教員の議論に基づいており、学生の学習ニーズと完全に一致しているかは検証が必要
- 異なるプロンプトで生成されたフィードバックの比較が未実施
- 医学画像教育に限定されており、他の科目への一般化可能性は今後の検討課題
- 倫理的影響や臨床教育におけるLLM依存の潜在的リスクへの対応が必要
結論
LLM生成フィードバックは、学生が自己のレポートを批判的に評価し、報告スキルを向上させるのを支援できる。LLMの適切な使用は教員の業務負担を軽減し、教育と学習の質を向上させる可能性がある。しかし、ハルシネーションや不正確さが依然として頻繁に観察されるため、教員による監督は不可欠である。
医学教育におけるAI活用は今後も進展していくと考えられるが、技術の限界を理解し、人間の専門家による適切な監督のもとで活用することが、効果的で安全な教育実践につながるであろう。